[This article was written for and accepted by RESAW Conference, “Web Archives as Scholarly Sources: Issues, Practices and Perspectives”, 8 – 10 June 2015, Aarhus University, Denmark.]
Introduction
Web Archives are collections of point-in-time snapshots of web resources, intended as historical records of the once current content on the “live” web, which constantly changes with old content disappearing and new content being added. Web Archiving started in the mid-1990s and was led by the US not-for-profit organisation Internet Archive, whose collection to date contains 456 billion historical web pages and continues to grow. Web Archiving has become a mainstream activity for many national memory institutions world-wide, supported by legislative frameworks such as Legal Deposit[1] to enable domain-level archiving for heritage purposes.
A general assumption is that web archives contain historical copies of websites. In truth, this describes more accurately the ultimate goal rather than the current state of web archives. Resources in a web archive are rarely identical to the “original” or the “live” websites. They are best described as records of point-in-time HTTP-level transactions between the webserver hosting the resources and the crawler software requesting them. Many events and decisions related to the capturing and replay process impact the degree to which the web archives resemble the original resources. Brugger and Finnemann consider archived web resources as “reborn”, similar to but different from the live web in many ways. [2]
In recent years, a group of pioneering researchers recognised the potential of archived web resources and started to explore this new category of scholarly sources. When engaging with these scholars, we realised that some characteristics of web archives raise conceptual and methodological challenges and are highly relevant to scholars’ interpretation of web archives. A fundamental oversight of the de facto user interface is that it focuses on replaying “text”. Very little is explained or explicitly stated beyond the actual HTML pages, including decisions which directly impact the completeness and resemblance between web archive and the original resources.
This article describes some important non-textual or “under the hood” aspects which are generally unknown to researchers and users of web archives. It argues that providers of web archives should in future make available such information and consider this as an integral part of web archives.
Crawl dates
Date and time when resources are captured or crawled are used to organise web archives, both at the level of internal structure and user interface. This adds a temporal aspect and allows the examination and analysis of resources over time. Crawl dates however, could be misleading and easily mistaken as dates of publication, while the two are almost entirely unrelated. Most web archives however, do not explain this to users, leaving room for misinterpretation. [3]
A decision by the European Patent Office in 2007 concerning a case involving an online game, where (printed out) archived resources from the Internet Archive were submitted as evidence, ruled resources retrieved from the Internet Archive could not meet the standard of proof without “further evidence concerning the history of the disclosure, whether and how it has been modified since the date it originally appeared on a web site.” One of the key factors contributing to this decision was the difficulty in establishing “date of availability”, which was not the same as crawl date and could not be ascertained with a reasonable level of confidence. Detailed reading of how the submitted URLs were accessed reveals a degree of misunderstanding about web archiving on the part of the Patent Office, something which could have been avoided with clearer explanation in the Internet Archive user interface.[4]
“Resource not in Archive”
“Resource Not in Archive” is the most common error message one comes across in a web archive. This is presented to the end-users when a requested URL cannot be found in the archive. This could be caused by many reasons, some of which are intentional, introduced by decisions such as data limitation or obeying robots.txt at crawl time; some are legal, relating to content beyond the scope or remit of the collecting institution; others relate to (unintended) technical limitations, e.g. dynamic content which the web crawlers are not capable of capturing.
The following examples illustrate the broad categories of scenarios contributing to content not being captured, leading to the “Resource not in Archive” message.
The British Library started implementing Non-print Legal Deposit of UK websites in 2013 by crawling annually the entire UK domain, consisting of over 10 million .uk registrations. A default per-host data cap of 512MB or 20 hops[5] is applied to our domain crawls with the exception of a few selected hosts. As soon as one of the pre-configured caps has been reached, the crawl of a given host will terminate automatically. Data volume limitation is a common way to limit or manage large scale crawls, which otherwise could require significant machine resources or time to complete. We also in principle obey robots.txt and META exclusions, unless for content required to render a page (e.g. JavaScript, CSS). Both decisions impact the scope of the UK Legal Deposit Web Archive.
Legal requirements can also limit the scope of a web archive and cause resources to be excluded from an archive. A good example of this is oneandother.co.uk, a website devoted to one of British artist Antony Gomley’s public art projects. The British Library obtained a licence to archive this website in 2012,[6] which only applied to resources hosted on oneandother.co.uk. The highlights videos on the front page were hosted on a different domain (skyarts.co.uk) and therefore could not be included in the Archive.[7] Another example is UK Non-print Legal Deposit, which only applies to UK websites, defined as those using .uk domains plus resources published by UK organisations and individuals regardless of the domain name. While transcluded resources are considered in scope, requesting resources linked to from the UK websites which do not meet the territoriality criteria would trigger the “resource not in archive” message.
Streaming media, embedded social network feeds and dynamically generated content are all challenging areas for web crawlers. Such contents are in general not captured and requesting them will lead to the “Resource not in Archive” error.
The above are the main reasons for incomplete capture of websites, which are shielded away from users in general. It is very difficult to map or determine the specific reason for each individual “resource not in archive” message. When designing user interface, thought needs to be given to the best way for informing users without overwhelming technical details, and for redirecting them to a satisfactory place to avoid navigational “dead ends”. [8]
Temporal inconsistency
The process of replaying archived resources is equally challenging and could further reduce the completeness of web archives. Some resources are captured but simply cannot be replayed due to a variety of reasons, e.g. lack of browser support for a certain file format. A more serious issue is the so-called temporary inconsistency or violation, resulting in pages marked with a single datetime but consisting of resources which were crawled at different times and never existed together. Ainsworth et al (2014) sampled 4,000 pages and concluded that at least 5% had temporary violation. [9] A temporal span of weeks or months is common between the oldest and the newest elements on a rendered page but in the most extreme cases, this measures as long as five or even ten years.[10]
Temporary inconsistency is best illustrated by the example below. Figure 1 shows a rendered page from the Icelandic Web Archive.[11] The frameset was captured in May 1998. The frame content, however, was captured in December 2000, two and half years later.[12]
 Figure 1. A page from the Icelandic Web Archive dated 1998
Figure 1. A page from the Icelandic Web Archive dated 1998
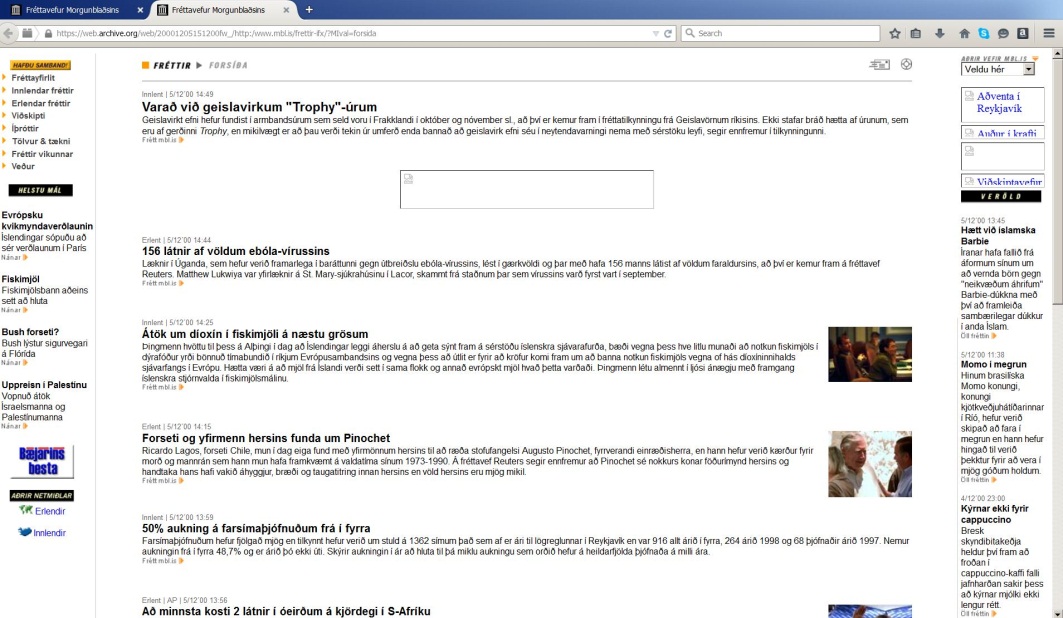
Figure 2. Frame content captured in December 2000
Temporal inconsistency mainly relates to the strategy or decision implemented in Wayback for serving or presenting resources.[13] Wayback is the common rendering software for archived web resources. When replaying a page captured at a certain date and encountering missing elements, it automatically patches the page together by using resources from the archive which are closest to the requested date. The motivation behind this approach may be the preference to present the users with something as complete as possible, instead of pages with “holes” or “gaps”. Or perhaps because temporary violation does not happen all the time and some degree of temporal drift does not matter. A different CSS file, for example would only alter the appearance of the rendered page, not the intellectual content. Similarly, changes in frameset, page footer or header would also not necessarily affect the interpretation of text, if this indeed is the object of study.
The fundamental problem with this approach is lack of transparency. Our experience with working with humanities scholars on the Big UK Domain Data for Arts and Humanities Project[14] indicates the desire to understand how things work behind the scenes and the ability of making own decisions and interpretations about the source. At least this is something that should be widely known, to researchers, users, curators and those who are not aware of this idiosyncratic feature of Wayback. Some historians even consider this a trust issue which affects their confidence in the authenticity of web archives. In addition, this approach fails to accommodate those scholars whose interest goes beyond the “text” and includes things such as CSS, page header and footer, which are considered as “paratext” and crucial to the textual coherence of a website.[15]
Ainsworth et al (2014) studied temporal violation in detail and offer a framework for assessing temporal coherence. This could be used by web archives to understand the temporal spread of their collections and make this information available to users, curators and researchers. Recent work by the Research Library of the Los Alamos National Laboratory attempts to make clear explicitly how a page is rendered and how it patches together resources from different web archives attached to the Memento Service.[16] When requesting http://www.bl.uk from 21 January 2004, the service first returns a list of web archives which have archived that URL, ranging from pages crawled 4 days before the requested date to 9 years 37 days after.[17] It also offers a “reconstruct” button, which uses 10 resources across 2 archives to patch together an as complete as possible page. The user interface indicates where the resources making up the page come from, when they were captured, and which, if any, are still missing – all these are visualised over a timeline.
 Figure 3. Memento interface showing http://www.bl.uk from 21 January 2004
Figure 3. Memento interface showing http://www.bl.uk from 21 January 2004
This greatly improves the understanding of web archives and enables more scholars to consider and find answers to the underlying conceptual questions: What exactly are archived web resources? Are they still valid as historical records, when taking into account their incompleteness and inconsistency?
Conclusion
This article attempts to communicate important aspects of web archives which used to be considered as operational and irrelevant to researchers and users, despite the fact that they raise conceptual and methodological concerns and impact the way scholars use and interpret web archives. The three issues described here are not exhaustive and only came to light when we worked closely with researchers. Web Archives are not archives in the classical sense. Properties of established (physical) archives such as authenticity and integrity, how truthful an archived resource is to the original, and how inviolable this is against modification, cannot be automatically assumed. The use of “archive” in its name, as a matter of fact, may not be appropriate as this implies a relationship with the traditional archive and raises expectations of a certain given quality. Web Archives are new to scholars too. Methodological frameworks and referencing standards are yet to be established for this new type of source which has potential and limitations at the same time. Before answers and solutions are found, maximum transparency remains the best remedy. Providers of web archives should realise the impact of technical and operational decisions on the nature and scope of web archives and no longer consider these data as “private” or irrelevant to users. Explanation of these should become base-line knowledge and integral parts of the web archive.
[1] Legal deposit is defined as “a statutory obligation which requires that any organization, commercial or public, and any individual producing any type of documentation in multiple copies, be obliged to deposit one or more copies with a recognized national institution”. http://www.ifla.org/publications/ifla-statement-on-legal-deposit.
[2] Brügger, N.; Finnemann, N.E., “The Web and Digital Humanities: Theoretical and Methodological Concerns”, Journal of Broadcasting & Electronic Media, Volume 57, Issue 1, 2013, http://www.tandfonline.com/doi/abs/10.1080/08838151.2012.761699.
[3] It is possible to obtain the “Last-Modified” date of the requesting object from the web server, and creation dates are sometimes embedded within web resources. However, this information has not been systematically collected and it’s reliability is unknown.
[4] European Patent Office, T 1134/06 (Internet citations) of 16.1.2007, http://www.epo.org/law-practice/case-law-appeals/recent/t061134eu1.html.
[5] Each page below the level of the seed, i.e. the starting point of a crawl, is considered a hop.
[6] Prior to Non-print Legal Deposit, the British Library requested permissions from website owners to archive and provide access to their websites.
[7] The archival version of the One and Other project website, http://www.webarchive.org.uk/wayback/archive/20100223121732/http://www.oneandother.co.uk/.
[8] When the “Resource not in Archive” message appears, a common help is to redirect users to the live web. The Open UK Web Archive offers an alternative memento service, to search across a number of web archives, which increases the chance to find a historical version of the resource (elsewhere).
[9] Ainsworth, S.; Nelson, M.; Van der Sompel, H., Evaluating the temporal coherence of archived pages, 2015, http://www.slideshare.net/phonedude/evaluating-the-temporal-coherence-of-archived-pages.
[10] Ainsworth, S.; Nelson, M.; Van der Sompel, H., A Framework for Evaluation of Composite Memento
Temporal Coherence, 2014, http://arxiv.org/pdf/1402.0928v3.pdf.
[11] Page from the Icelandic Archive with single daytime of 1998, provided by Kristinn Sigurðsson of the National Library of Iceland, https://web.archive.org/web/19980507193528/http://mbl.is/.
[12] Direct access to frame content, captured in 2000, https://web.archive.org/web/20001205151200fw_/http://www.mbl.is/frettir-ifx/?MIval=forsida .
[13] Temporal inconsistency could also take place at crawl time. This happens when the rate of capturing is exceeded by the rate of change on a website. Changes to resources on a website could take place during a crawl, again resulting in high-level inconsistency across pages which did not co-exist at a given point in time. Temporal inconsistency occurring at crawl time is hard to detect.
[14] Big UK Domain Data for Arts and Humanities Project, http://www.buddah.ac.uk.
[15] Brügger, N., Website Analysis: Elements of a conceptual architecture (Aarhus: The Centre for Internet Research, 2010).
[16] About the Memento Project, http://mementoweb.org/about/.
[17] Mementos of http://www.bl.uk, http://timetravel.mementoweb.org/list/20040121190250/http://www.bl.uk/.

[…] This article was written for and accepted by RESAW Conference, “Web Archives as Scholarly Sources: Issues, Practices and Perspectives”, 8 – 10 June 2015, Aarhus University, Denmark. […]
LikeLike